Blackhat 2022 線上遊記
BlackHat,這個資安圈盛會,也一直是自己學習資安的路上一個嚮往和期待能參與的活動,但對於學生來說,費用相較昂貴而且參與成本較高,尤其是在疫情當頭的 2022 年,能參加更是一種奢侈…,但是!今年感謝 Orange Tsai 願意給我講者的學生推薦票,讓我有機會線上參與這場活動 (因為是役男不能隨便出國 QQ),所以我就來紀錄一下這次的線上遊記吧!也希望藉由這個簡單的紀錄,讓更多人知道究竟 BlackHat 上會有什麼,跟我藉由這次參與兩天的議程,有什麼收穫跟感想。
前言
- 在大四即將畢業的今年,剛好也是學習資安這條路上的第三年,其實對於未來也有些迷莽,由於自身也有接觸 AI 的相關領域,其實一直希望研究 AI + Security 這條路,但對於這條路上會需要的知識跟技能,還有發展方向都不是很清楚,也不確定世界是不是需要這樣的人,在台灣的很多 Conferences (HITCON、資安大會等等) 其實都有對應的議題議程,但對於正個世界而言,是不是真的有需要,還是只要好好學好資安在跨足把 AI 當工具就好,這些困擾一直在我心頭,也一直希望有機會聽聽看國際議程,更了解世界正在發生著什麼,跟需要怎樣的人。
- 這時剛好看到 Orange 大大願意讓大家爭取他的學生推薦票去參加 BlackHat 2022 USA,抱著試試看的心情填寫了問卷並且表達了自己對於相關議程的興趣之後,Orange 大大願意給我這個機會去看看 BlackHat 這個盛會正在討論著什麼,雖然因為各種原因只能線上參加,但能獲得這個機會實在很難得也很感謝,因此要特別感謝 Orange 大大願意給這個機會,因為這次聽完議程,有更加理解自己能做什麼跟 AI Security 究竟是什麼。
- 由於這次真的太多東西可以分享了,因此我大打算藉此機會寫一系列相關的文章,分別是內部的技術分析跟我自己的理解,因此這篇作為開場會 Summary 關於這次我聽的議程的一些大綱,然後會再 link 到我自己另外想討論的內容~
- 這邊挖了坑但是也要說聲抱歉,很多東西都還在學習中,因此可能會有一些錯誤的地方,如果有任何問題或是想討論的地方,歡迎在下方留言討論~
議程
Day 01
Keynote: Black Hat at 25: Where Do We Go from Here?
[time= Aug 10, 2022 09:00 to 10:00]
- Jeff Moss,Black Hat 的聯合創辦人為我們進行了精彩的開場,很榮幸今年是我第一次參加 Black Hat 卻剛剛好是 Black Hat 創辦的地 25 個年頭,Jeff 有特別說到 25 年是一個很重要的里程碑之一,1/4 個世紀以來整個環境有許多改變,很多事情正在慢慢明瞭中,但仍有許多未知的事物等著所有人去理解探索。
- Jeff Moss 在開場提到了一個很重要的事情,那就是網路世界或者說整個世界已經有根本性的改變,Jeff 提到了訊息監管和網路權威等等的資訊跟議題,究竟是更完善完整的訊息才是重點還是適當的資訊限制才對人們有利呢?也提到了現在其實有一股力量,被他稱為 super empovered organization,擁有巨大的影響力,他們有權利有能力跟你的 mail server 的 spam block list 一樣創建一個阻擋清單。Jeff 利用這次的烏俄戰爭作為例子,當人們決定懲罰戰爭罪的時候,當人們覺得政府並不夠積極的時候,發生了什麼事情? MongoDB 刪除了所有跟俄羅斯有關的項目、數據,公司將以一個超高影響力的角度進駐社群改變生態也都是可能的,而且這件事情會越來越明顯,越來越強勢。Jeff 提到正因為這些事情的發生,讓他提議發起一個監管組織,來制定所謂的 block list,這樣才能更針對性的制裁或者控制影響範圍,例如假設今天有這個監管組織,MongoDB 就不會移出所有俄羅斯的 Database,而是說,我們基於這個 block list 禁止了特定 IP 的訪問,這樣就不會影響那些無法改變任何事情的普通民眾。但這件事情就如一個魔盒,有些事情並不是被期望攤出來說的,我們期望政府監管,但我們也在種種地方看到政府無力影響龐大的公司決策,但 Jeff 也狠狠的說明,當政府無能時,會有人接手填補空白,上述資訊說明了世界的互動已經有了截然不同的改變,很多事情不再如我們預想的一般運行,影響力巨大的世界互動慢慢在改變著世界。
- Chris Krebs 開始了接下來的演說,整個核心主題我認為說明到了現在的狀況和未來其實應該注意的部分,現階段的產品設計或者說公司主軸都還是認為產品的搶先對於市場對於賺錢而言有至高無上的地位,這當然沒錯,但這樣搶快的開發根本性的造就了現在架構上的混亂,當然,這些風氣正在因為越來越嚴重的資安事件跟勒索病毒有所改變但這些改變仍然太慢,公司領導必須放眼到 2~3 年後的世界變化,應該能更加重視接下來 2~3 季可能發生的攻擊、可能發生的國際情勢變化,我們無法忽視各種數據正在加速擴展的事實跟這些資料都是攻擊者的目標,俄羅斯對烏克蘭的攻擊、中國跟台灣的緊張關係都正說明世界的改變其實並沒有依照原設想的劇本走,資訊安全有許多期望跟需要努力的方向,都一一在這個演說中被強調出來。
My Comment
- 身為兩次實習都是在傳統科技廠的我來說,我完全能夠理解公司內部為何對"資訊安全"不在意的原因,因為嚴格的資安限制跟監管就是對於開發還有人員的一個巨大挑戰,公司是不是在意資安,是,他們非常在意,但在瞬息萬變的市場趨勢中,如果我能快別人一小步開發出產品,是不是就能改變市場改變世界,其實是的,因此在所謂的賺錢部門跟開銷部門的博弈中,資安往往是能被忽略的,不是說不在意跟不重要,是當必須做出取捨時,他會被毫不猶豫地丟棄。
- 在我的角度,如和取得平衡跟如何最小影響的一直提醒開發人員反而是資安部門需要理解跟考慮的議題,例如資安檢查的自動化跟建議,還有在不影響開發的狀況下的提醒,似乎是專注於資安的我們需要去考慮的跟調整的思維,一味的要求開發人員去培養資安思維是不切實際的,不是說不要求,而是當他們忘記時,我們是否有機制跟方法去自動化的檢查跟提醒修正,似乎更加重要。
- 良好的 DevOps 跟 CI/CD 的建立,我認為是開發上防守的第一步,更好的 Quality 的程式碼跟更安全完整的 Review 流程,都是不可或缺的一環,再外加安全的開發環境跟基本社交工程防禦意識 (由資安人員建立的安全內網環境,還有釣魚信件的意識培養等等),其實就可以加強公司的資訊安全狀況,我們無法忽視資安問題,但當資安跟開發兩者有所抵觸時,換個思維去思考是不是能讓資安公司跟其他企業們不再是對立,而是共同發展的合作夥伴。
All Your GNN Models and Data Belong to Me
[time= Aug 10, 2022 10:20 to 11:00]
- Notes
- Message Passing Technology
- GNN
- Graph Converlution Network
- Graph Isomorphism Network
- Euclidean space 歐幾里得空間
- Adversarial Machine Learning 對抗式機器學習
- The big topic of the security of machine learning themselves
- Privacy - Graph
- Link Re-Identification Attack 鏈路重識別攻擊
- Property Inference Attack 屬性推理攻擊
- Subgraph Inference Attack
- Secure - Model
- Model Extraction Attack
- 本分享主要在說明一個利用公司提供的 GNN API 就可以針對其中的 Graph & Model 盜取,由於涉及到大量的 GNN 基礎知識,因此這邊預計會寫一篇 GNN 的說明文章,大家可以去閱讀一下,應該會更好理解我這邊說明的部分
- 這邊大致上針對這個 Speach 說明一下幾個核心重點,因為有 Release PPT 因此下面會直接截圖 PPT 內容,完整 PPT 請去官網連結獲取。
- 這次的攻擊主要分成針對 Graph 的 Privary Attack,專注在利用 Link Re-Identification Attack、Property Inference Attach、Subgraph Inference Attack 來做 graph stealing,然後也可以直接利用 Model 的 Secure Attack 則是應用 Model Extraction Attack 做到輸出值做梯度下降來擬合建立的假 model 做目標 model 結構推估,而且可以利用約 1/4 的 network size 做到只有 3~5% 原始 model 的誤差的模型。
- 這邊的很多細節都還不知道是怎麼做到的,會藉由寫其他 Blog 來理解跟完善。
Last update at 2022-12-12
My Comment
- 我聽完這場議程後最大的感想是因為 GNN 的模型特性,如果不做一定程度的輸出混淆,確實真的很容易被利用這樣的方式把 model 的 graph dataset 跟 model structure 給整個偷出來,但是這整個想法真的是非常非常的特別,因為我從來沒想到可以利用後接一個 network 作為收斂函式就快速收斂逼近模型結構。那由於議程講者有說他們有提供緩解解法了,因此我現在想到針對這個做法的應用反而可以是公司端利用這個技術來優化縮小 model size,因為有時候 3~5% 的 model acc 誤差是完全可以接受的,但是 model size 只要 1/4 卻是對於硬體設備有極大的優勢跟誘因,因此雖然現在這個可能慢慢不是 security issue 卻仍然可以是一個非常天才非常令人讚嘆的作法,來優化模型結構。
- 而利用 API 來做 Model Stealing 其實並不是第一次了,這也是為什麼例如 Google Image Search 會利用一套流程來隨機輸出錯誤的 Mapping Data 來避免 Model 被 Leak 出來,這個議題已經是很早就已經被注意的議題,因為 100% 的輸出結果意味著我可以建構特定輸入資料來推出輸出。
Glitched on Earth by Humans: A Black-Box Security Evaluation of the SpaceX Starlink User Terminal
[time= Aug 10, 2022 11:20 to 12:00]
In Need of ‘Pair’ Review: Vulnerable Code Contributions by GitHub Copilot
[time= Aug 10, 2022 13:30 to 14:10]
- 本場議程主要是在說明 GitHub Copilot 的推薦程式碼並不是安全的程式碼。GitHub Copilot 是一個 GPT-3 的 code completion service,可以幫助開發者快速完成程式碼的撰寫,但這邊有個問題,那就是 Copilot 所推薦的程式碼並不是安全的程式碼,例如下圖 Example,GitHub Copilot 推薦了最常見的 SQL Injection 漏洞程式碼 (輸入字串串接),那為什麼會有這個問題,還有究竟 GitHub Copilot 是如何運作的呢?
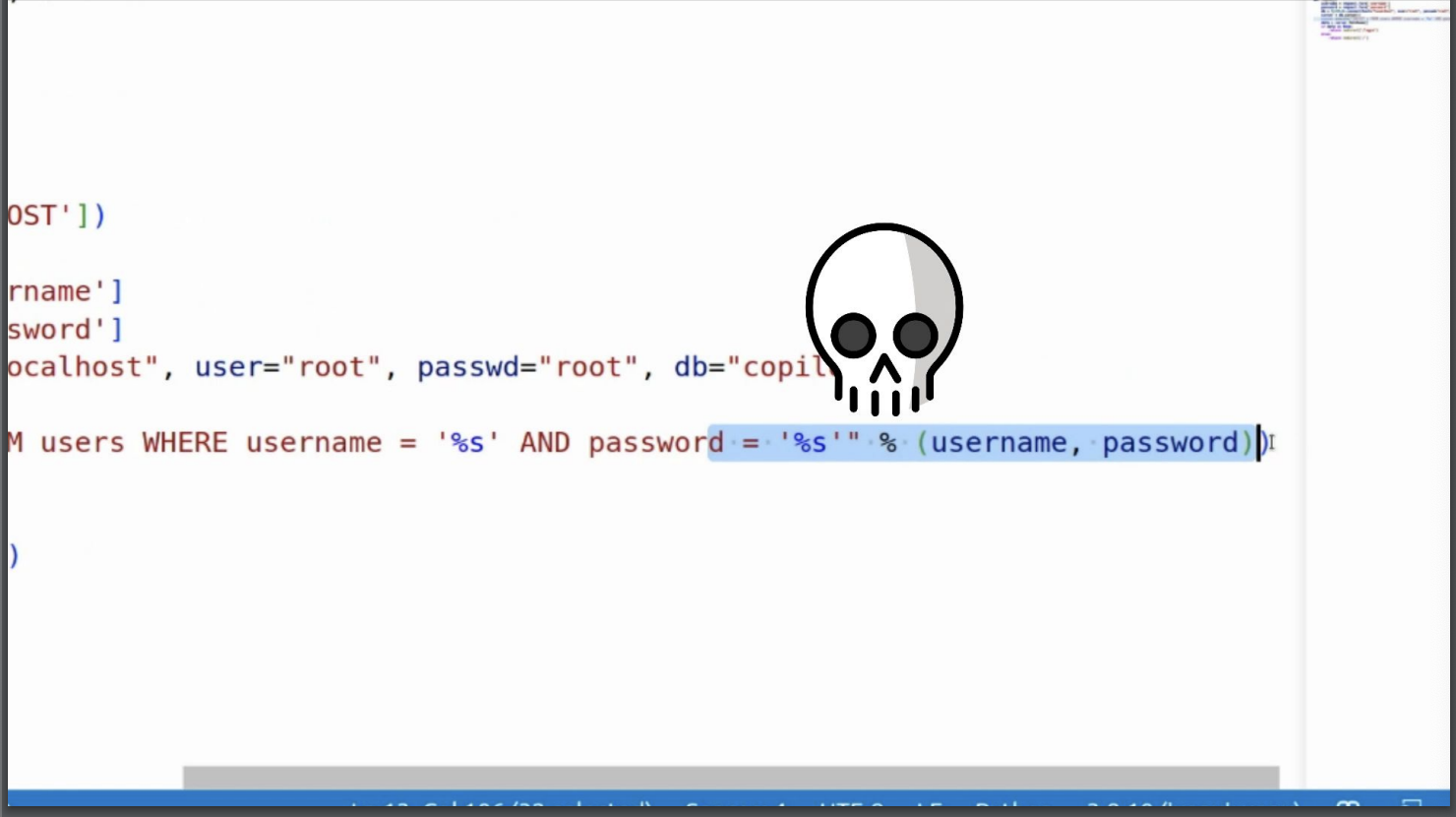
- 上面有提到 GitHub Copilot 是一個 GPT-3 的 Code version model,那今天 Copilot 是怎麼知道要推薦我們什麼樣子的程式碼呢?如下圖舉例,在接收到我們的程式碼輸入之後,他會有一個文字清單來做輸出,但這個清單的每個單字應該出現的機率是不同的,Copilot 會選擇機率最高 (最合適) 的程式碼做推薦並且往下推舉,來建構應該推薦的程式碼片段。

- 那到這邊聽起來沒什麼問題啊?Copilot 確實推薦了最有可能性的程式碼,而且是可以正確運行的程式碼,問題在哪裡?最大的問題在於他推薦的是"可以使用的正確程式碼"而非"正確安全的程式碼"。
- 針對這個問題,議程的發表團隊設計了一個實驗流程來驗證 Copilot 的推薦程式碼是否安全,實驗流程如下圖所示,並且希望利用這樣的實驗流程來調查驗證三件事情,分別是
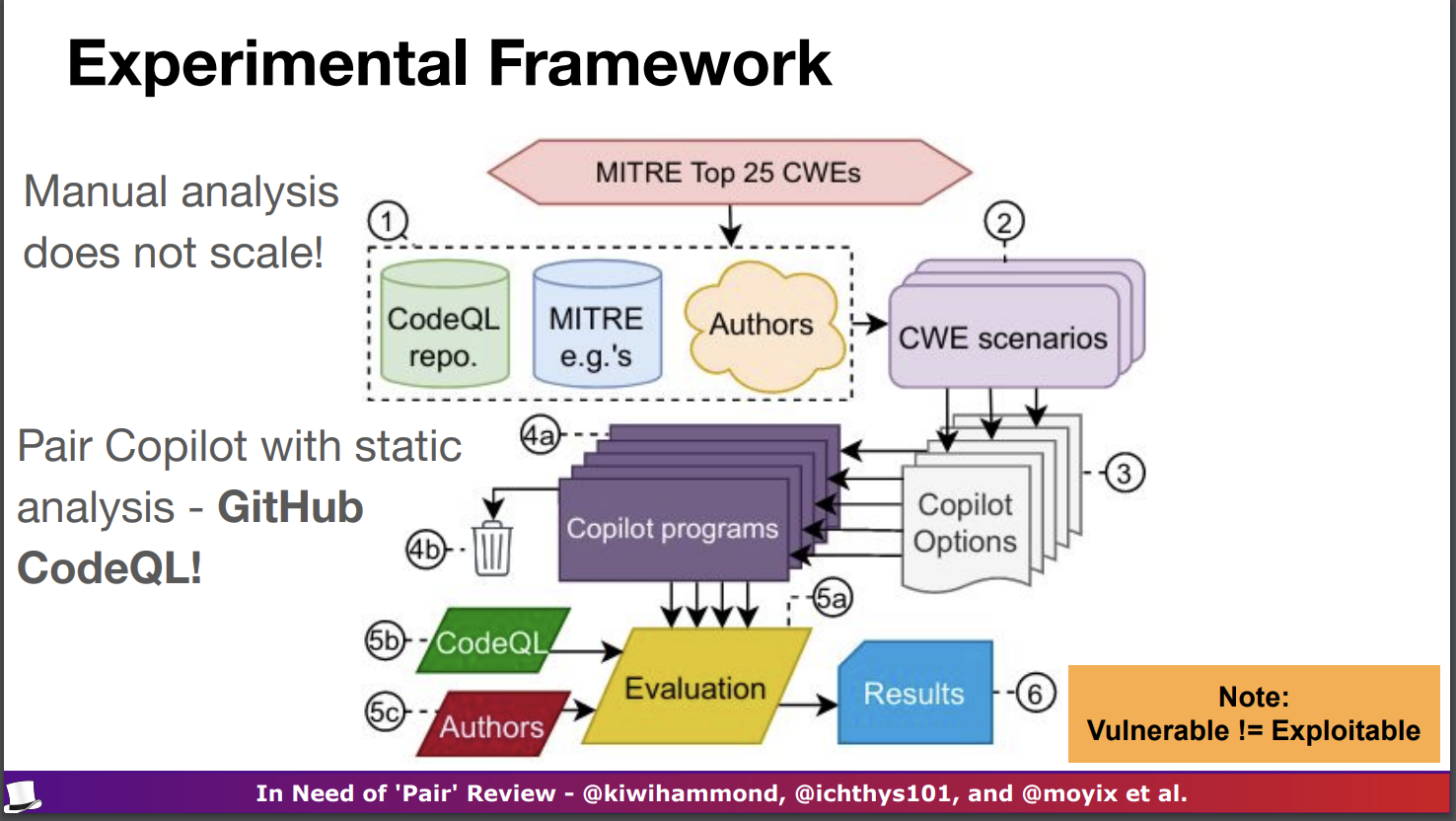
- 弱點的多樣性 - Diversity of Weakness: 不同類型的漏洞發生的機率是多少?
- 提示的多樣性 - Diversity of Prompt: 提示的變化會改變漏洞的發生率嗎?
- 領域的多樣性 - Diversity of Domain: 這種發現在 Software 以外的領域有發生嗎? 並設計了驗證指標,分別是
- 有效性 - Valid: 也就是 Copilot 返回的可運行程式碼數量
- 脆弱性 - Vulnerable: 也就是這些返回中有多少有 CWE 漏洞
- 最佳建議狀況 - Top Suggestion: 第一個 (也就是最推薦的)可運行建議安全嗎?
- 後續的實驗概述就可以請大家自己去看 Public 的 Slides 了,很明顯的事情是推薦的狀況並沒有預期中的良好。
My Comments
- 在我的理解中,Copilot 會發生這樣的非安全性程式碼推薦是很正常的一件事情,大家應該都有把剛學習的時候的 hello world 程式碼推上 GitHub,這種所謂的練習 or 根本沒有安全意識的程式碼在 GitHub 上的數量可以說是非常非常巨量的,而利用 GPT-3 對這樣大量的程式碼做學習,在他的理解中,這些 code 確實都是可以執行的 “好程式碼”,既然如此,推薦這些程式碼來完整我們缺漏的部分當然是很合理的。
- 這是不是需要關注的議題,當然是,因為在資訊安全的領域中,好從來就 != 正確,那究竟有什麼解決方案呢?其實不外乎就是不要完全相信 AI 推薦的程式碼,可以借用推薦的邏輯,但要記得修改成 Quality 更高的程式碼,這樣的做法其實是很常見的,例如在我們的開發流程中,我們會使用 Code Review 來確保程式碼的品質,這個過程就是在確保程式碼的品質,而不是完全相信 AI 推薦的程式碼。
- 對於 model 的部分來說,當然就是要更多的資料前處理跟人員審核,才能更好的避免這個問題的發生,當然,成千上萬的 GitHub Repo 中要避免這個問題,實屬困難,因此只能期待於後期慢慢修正並且這個問題被解決,或是有更好的解決方案。
Return to Sender - Detecting Kernel Exploits with eBPF
[time= Aug 10, 2022 14:30 to 15:10] Tool Link
- 本議程主要是在說明 Kernel Exploits 利用 Kernel 內建的 eBPF (Extended Berkeley Packet Filter) 來做檢測攻擊,這個議程的內容其實是很簡單的,就是在說明 eBPF 的基本概念,以及 eBPF 的問題、攻擊狀況。
- eBPF 是 Kernel 的 Sandbox,可以允許我們在 OS Kernel 中運行 Sandbox Application。它用於安全有效地擴展 Kernel 的功能,而無需更改 Kernel Source Code 或 Loading Kernel Modules。
- eBPF 的強大之處在於,他可以完全模仿 Kernel 的操作但確保安全性,例如錯誤的 Kernel Space 對 User Space Address 調用之類的問題,但也有問題就是 eBPF 對於 System 來說是一個負擔,因此會導致 Kernel 效能下降。
- 因此講者今天提出了一個新的工具框架,叫做 KRIe (Kernel Runtime Integrity with eBPF),旨在有限的預算和運作效能中,應用 eBPF 來檢測 Kernel Exploits,並且最大化降低對系統的負擔狀況。
My Comments
- 會選擇這個議程的原因是因為剛好有在修 Linux Kernel 的課程,並在議程中第一次聽到 eBPF,對於議程並沒有很聽懂,但可以發現到 eBPF 的應用場景原來可以從一個單純的 Sandbox 延伸出去做到防禦跟檢測 (錯誤的記憶體位置操作)。
Fault-Injection Detection Circuits: Design, Calibration, Validation and Tuning
[time= Aug 10, 2022 15:30 to 16:10]
- 這場議程是關於 Fault-Injection Attack (故障注入攻擊),在這場議程之前我是完全沒聽過這個東西的,因此覺得很新鮮。
- 提到了 Non-Invasive FI Attack (非侵入式故障注入攻擊)、Semi-Invasive FI Attack (半侵入式故障注入攻擊)、Invasive Physical Attacks (侵入式物理攻擊),
- 其中 non-invasive FI attacks 主要是在不對封裝進行影響的攻擊,因此主要能接觸的部位為封裝外部的 clock 跟 voltage pins (針腳),攻擊有包括
- Voltage attacks - 電壓攻擊
- Clock attacks - 時鐘攻擊
- EM (Electro-mangnetic radiation) attacks - 電磁輻射攻擊
- Thermal attacks - 熱攻擊
- 而 semi-invasive FI attacks 的主要攻擊設立用 Lasers (雷射),因為需要對封裝進行開蓋,但研究表明可以從封裝的側面再不開蓋的狀況下執行此攻擊。
- 而 invasive physical attacks 則主要利用 FIB、etching (蝕刻)、on-die probing 等等方式來進行攻擊。
- 其中 non-invasive FI attacks 主要是在不對封裝進行影響的攻擊,因此主要能接觸的部位為封裝外部的 clock 跟 voltage pins (針腳),攻擊有包括
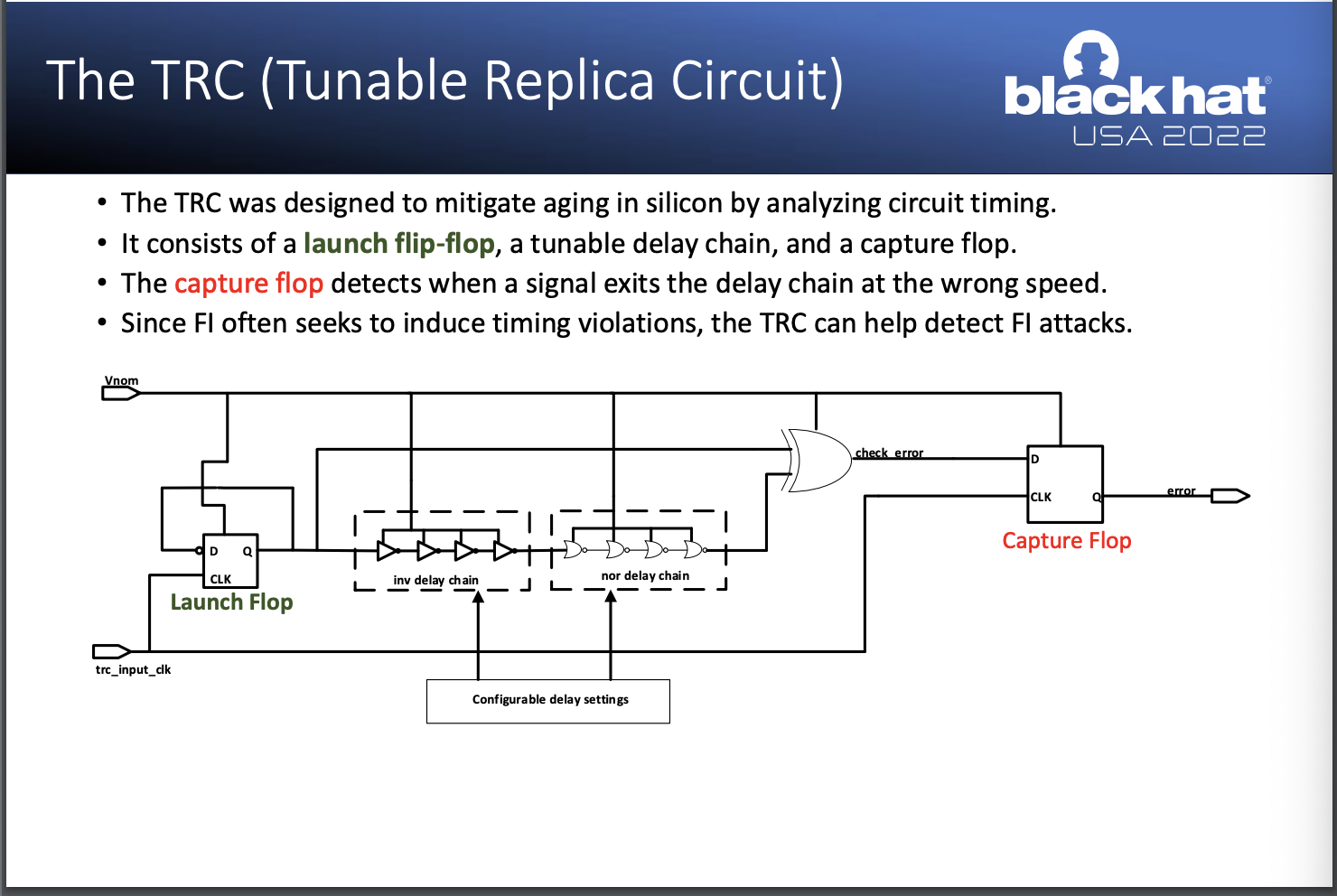
- 而使用 FI 攻擊的共同目標是造成 circuit timing 的失效而不是造成平台損毀。當 circuit timing 失敗時,資料可能會被過早或太晚的 latched,這時就可能造成例如在 fixed-function crypto engines 的 real key 有機會被替換。
- 針對這個問題,Intel 選擇了 Tunable Replica Circuit (TRC, 可調式複製電路) 作為一個檢測錯誤 or 攻擊發生的解決方案,原因在於 TRC 本身有一個 Capture Flop 在攔截檢測訊號是否有發生異常,而這個 Capture Flop 同時也將檢測到 FI Attack。
My Comments
- 因為硬體層面的資訊安全,我覺得是一個很有趣的領域,但是我自己的知識不足,因此這次的議程我覺得很有趣,但是也沒有很深入的理解,因此我會再找時間來研究這個領域。
- 但自己比較有感觸的就是硬體層級的資訊安全其實也非常重要,在修交大 Computer Security 課的時候,在密碼學就有提到旁通道攻擊這種側錄硬體運作時電壓狀況的攻擊,本身之前在實習時因為公司是 Server 相關公司,也聽過正在研究所謂的硬體層級的資料加密應用,因此 Chip Security 或者說 Hardware Security 也是非常重要的一個領域。如何避免外力干擾而正確驗證資料流,或者避免外力介入偷取傳輸資料等等,都可以說是這個領域的核心問題 (在我的理解),而 Intel 這次希望解決的問題就是被替換 or 影響到資料流的狀況。
GPT-3 and Me: How Supercomputer-scale Neural Network Models Apply to Defensive Cybersecurity Problems
[time= Aug 10, 2022 16:30 to 17:10]
- 此演講主要在呈現跟說明 Machine Learning 的 Model 跟 Self-supervised Learning Model 正在改變這個世界,本演講是一個很純粹正在說明 Machine Learning 跟 Security 這個領域的火花的演講,兩位 Speaker 都是這個領域的佼佼者。
- 先講結論,這次演講呈現的結果是成功利用 GPT-3 這個 NLP Model 對指令列做解讀翻譯成人類更好理解的語句,並且效果顯著。在 F1-Score 上取得了 0.95 的成績,非常亮眼。
- Self-supervised Learning 的概念是利用 Model 自動化標記資料,並且把標記完的資料當作 Training Data 去將 Unsupervised Problem 變成 Supervised Problem 來做解決。而在這個過程中,人工慢慢介入來修正標籤,讓 Model 在這個過程中越來越好並且輔助標記更多資料來重新訓練,在這個循環中持續提高準確率。聽起來跟 Semi-supervised Learning (半監督式學習) 很像,但其實兩者有根本上的差異,Semi-supervised Learning 是利用少量的 Labelled Data 來訓練 Model,並且利用 Unlabelled Data 來增加 Model 的準確率,而 Self-supervised Learning 則是利用 Unlabelled Data 來訓練 Model,並且利用 Labelled Data 來增加 Model 的準確率。
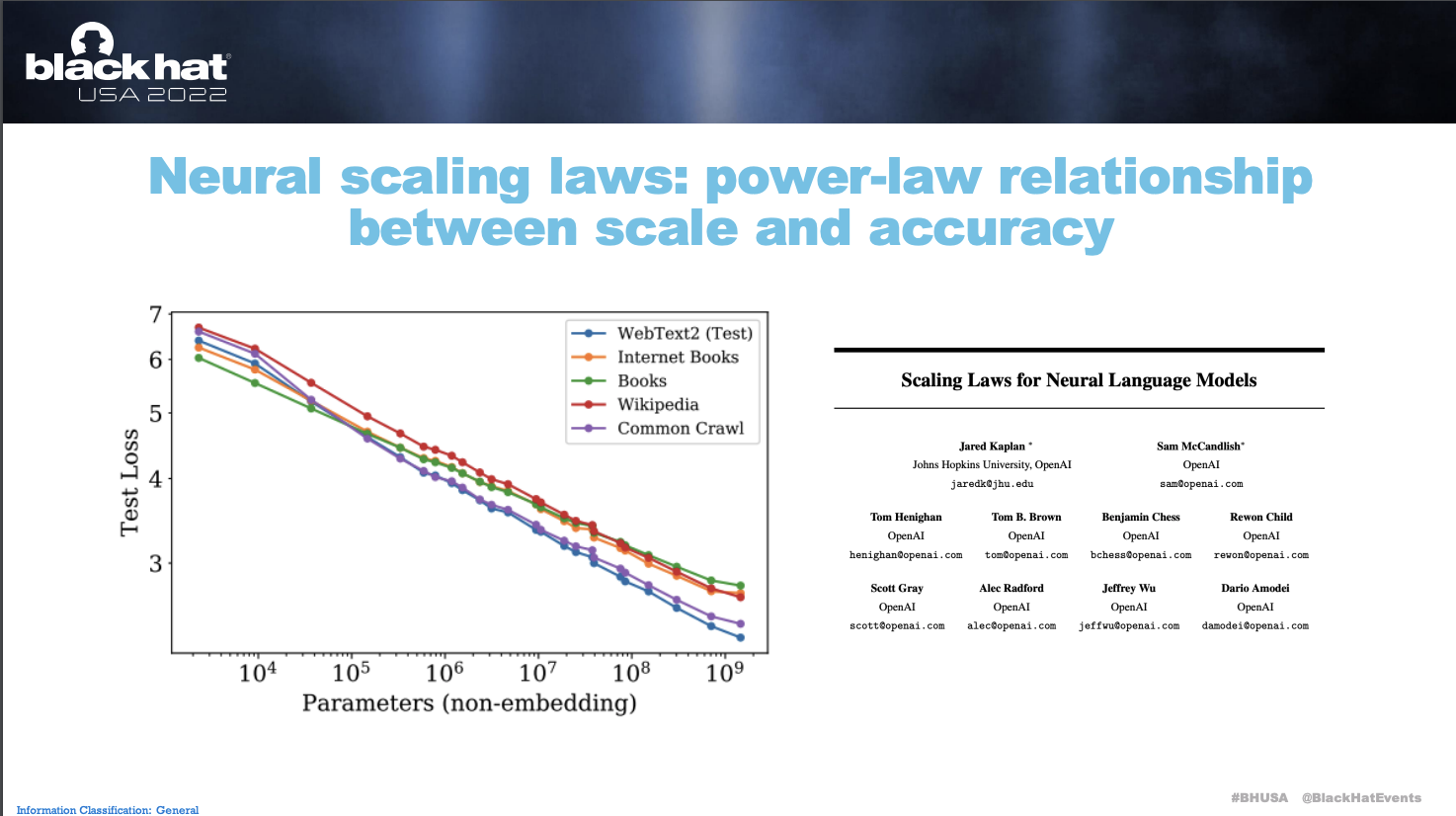
- 而在演講中有提到一個很重要的事情就是 Model Size 的成長,Deep Learning 的發展本來就是依靠於神經元的數量跟神經網絡的深度來強化特徵分析,也正是因為如此,演講中有提到對於同樣的敘述,模型神經元的數量的差異會對資料有多大的影響,如下圖:

- GPT-3 在 Model Scaling 的加成之下有一個非常恐怖的增長,例如文本跟程式碼的關聯性補齊等等,舉例來說 GitHub Copilot 就已經能從我們的註解中理解並且幫我們撰寫出很高品質 (非安全性的品質) 的程式碼了。從 Neural scaling laws 中可以看到,當 Parameters 越多,Loss 理應越低。
- 演說中也提到了 Self-supervised Learning 為什麼對於 Security 領域有很重要的發展在於,對於 “以前沒有發生過的攻擊類型的偵測的發掘” 有很重要的幫助,基於 Self-supervised Learning 本身的特性,Model 本來就會嘗試去找出資料中的 Pattern,而我們的介入是微調他們的 Self Labeling 來讓模型收斂的更漂亮,因此對於資料延伸的推估是非常強勁的。而以前這件事情並不是一個輕鬆的工作,但因為 Model Scaling 的原因,準確率跟效果越來越好。針對應用的部分演說中舉例了利用 GPT-3 針對垃圾郵件的檢測分類、對於惡意 Payload 的可讀性解釋生成等等,這些都是非常有趣的應用,而且也是我們在日常工作中可以利用的工具。
- GitHub of the speach: https://github.com/sophos/gpt3-and-cybersecurity
My Comments
- GPT-3 這個 NLP Model 在各種領域的發展影響的越來越深了,不管是聽演講的當下 Microsoft 已經在 GitHub 上推出了 Copilot 這個 GPT-3 的 Code Complition Application,又或者在寫 Blog 的當下由 OpenAI 所推出的超強對話引擎 ChatGPT,都說明了這種 NLP Model 對於生活中的領域應用越來越多,而且都有著強大的效果,這次的演講提到了利用 Payload 生成 Human Readable Sentences,那其實在其他論文中也有嘗試在 Human Readable Information 提取成 Keywords 的部分。這些其實就是 Model 發展對於各種領域的加強,而應用在繁雜的程式語言世界中,也越來越有效果。
Day 02
Keynote: Pre-Stuxnet, Post-Stuxnet: Everything Has Changed, Nothing Has Changed
[time= Aug 11, 2022 09:00 to 10:00]
Do Not Trust the ASA, Trojans!
[time= Aug 11, 2022 10:20 to 11:00]
Oops..! I Glitched It Again! How to Multi-Glitch the Glitching-Protections on ARM TrustZone-M
[time= Aug 11, 2022 11:20 to 12:00]
- 這場議程也說到了硬體的安全問題,也說到了 故障注入 (Fault Injection, FI) 的攻擊手法,期待造成 IC 環境發生快速變化,從而導致特定的、可利用的惡意行為。並提到了四個常見的 FI,
- Clock-FI
- Electro-Magnetic FI
- Laser FI
- Voltage FI
- 並提到了一個常見的 FI 防禦手法就是利用 重複暫存器 (Duplicated Registers) 的方式,進行狀態校驗,來驗證是否有任何故障的發生 (不只是是否有 FI 發生)。
- 這個議程提到了 MFI 也就是 Muti Fault Injection 多重故障注入攻擊時,有辦法在利用最少 3 Voltage FI 來完成個有做到 Duplicated Registers 的繞過。
My Comments
- 一樣是對硬體 Security 的問題,由於自己對於這個領域的理解不夠,因此沒辦法很好理解全部的議程內容,因此不是很清楚關於 TrustZone-M 那邊的結構狀況,但因為上面的其他議程有提到類似的硬體安全也提到了 FI 的攻擊手法,那個時候並沒有提到這個議程裡面提到的 Duplicated Registers 的防禦手法,因此這個議程的內容對於我來說是新的,也是很有趣的。
The Battle Against the Billion-Scale Internet Underground Industry: Advertising Fraud Detection and Defense
[time= Aug 11, 2022 13:30 to 14:10]
- 此場議程主要在討論惡意廣告的操作手法,並且討論是否有辦法建立檢測跟防禦手法。
- 在提到了廣告商是如何購買廣告,而平台商又是如何呈現廣告,並依照案例提到了
- 在正常服務商的 SDK 中被載入惡意軟體的問題。
- PC 端軟體安裝程式中被綁定惡意軟體的問題。
- 各種惡意廣告點擊的工具。
- 其中有一個很核心的部分在於瀏覽器再提供畫面時,被不管是
- 環境建構 - 醒目字體 or 醒目顏色 的惡意廣告滲透。
- 瀏覽器資料獲取漏洞 - 透明的惡意廣告滲透。 其核心都在於現階段資料呈現的過程中,有太多部分可以被調整並且滲透惡意廣告,而供應商還有畫面呈現的 Browser 都沒有對這些資料做檢查,所以就造成了這些問題。
- 詳細案例說明跟檢測可以直接看議程提供的 Slides。
My Comments
- 我覺得廣告呈現的供應商應該有一套檢查 and 驗證的機制在提供廣告 and 調整資料呈現,而不是只為了賺錢而提供浮誇且甚至故意希望我們點擊進入的廣告,舉例來說大家應該都看過很多新聞網站,他們都會有浮誇的彈出式廣告在運作,這種就是廣告供應商的惡意,詳細廣告種類這個議程也有說明,真的很多元很可怕。
- 而廣告的未審核更是惡意,之前就有 Telegram 的惡意程式偽裝成真的 Telegram 並且購買廣告之後,於 TG 檔案內放置惡意程式,這種明顯不是集團購買的廣告 Google 也沒有審核跟阻擋,其實也造就了惡意廣告層出不窮。
- 一套正規良好的檢測跟防禦機制是必須要的,只是如何更好的且有系統地列出不管是黑名單 or 任何檢測流程,都還是需要努力的目標,甚至,這個強度應該不是一個組織 or 研究機構就可以成功的,更多是大家的聯合。
Malware Classification With Machine Learning Enhanced by Windows Kernel Emulation
[time= Aug 11, 2022 14:30 to 15:10] Github Link
- 這場議程主要在討論的就是靜態惡意程式分析常見的所謂的混淆、路徑偵測等等的問題,是不是有新的解決方案 or 別的解決思路可以避免掉,並且提到了他們於內部的實驗跟嘗試。
- 靜態程式分析 or 惡意程式偵測主要會遇到幾個常見的問題,分別是
- 對抗性機器學習 - Adversarial Machine Learning
- 打包 - Packer
- 混淆 - Obfuscation
- …
- 還有所謂的正確狀況跟惡意狀況非常近似的問題,例如
- 惡意路徑 == 一般正常路徑
- 惡意程式 依附於 正常程式
- …
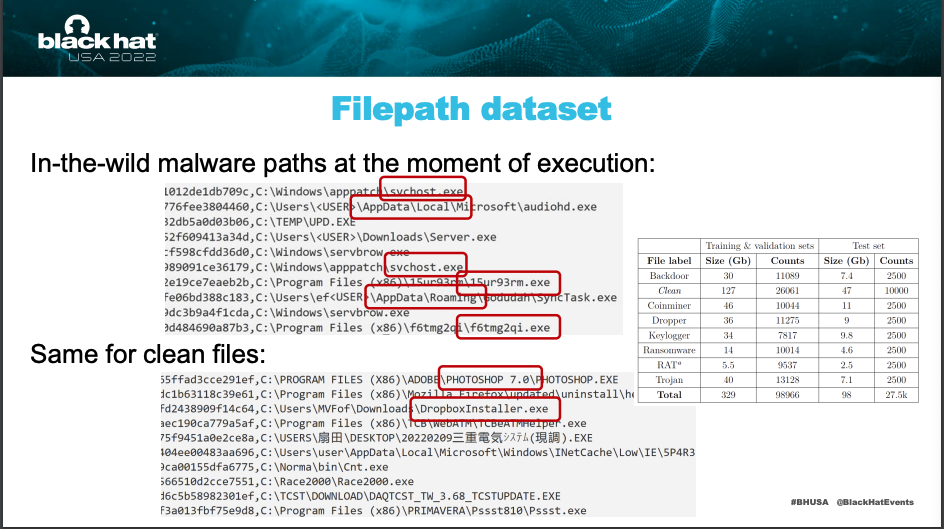
- 在 Dynamic & Contextual Analysis 的狀況之下,我們還有機會偵測辨識出一些特徵 or 發現一些奇怪的操作,如下

- 那 MS 團隊利用了 1d converlution 的方式針對做過 Embedding 處理的 path string 做分析,在 3 個月的 training 之後得到了一些成果,如下
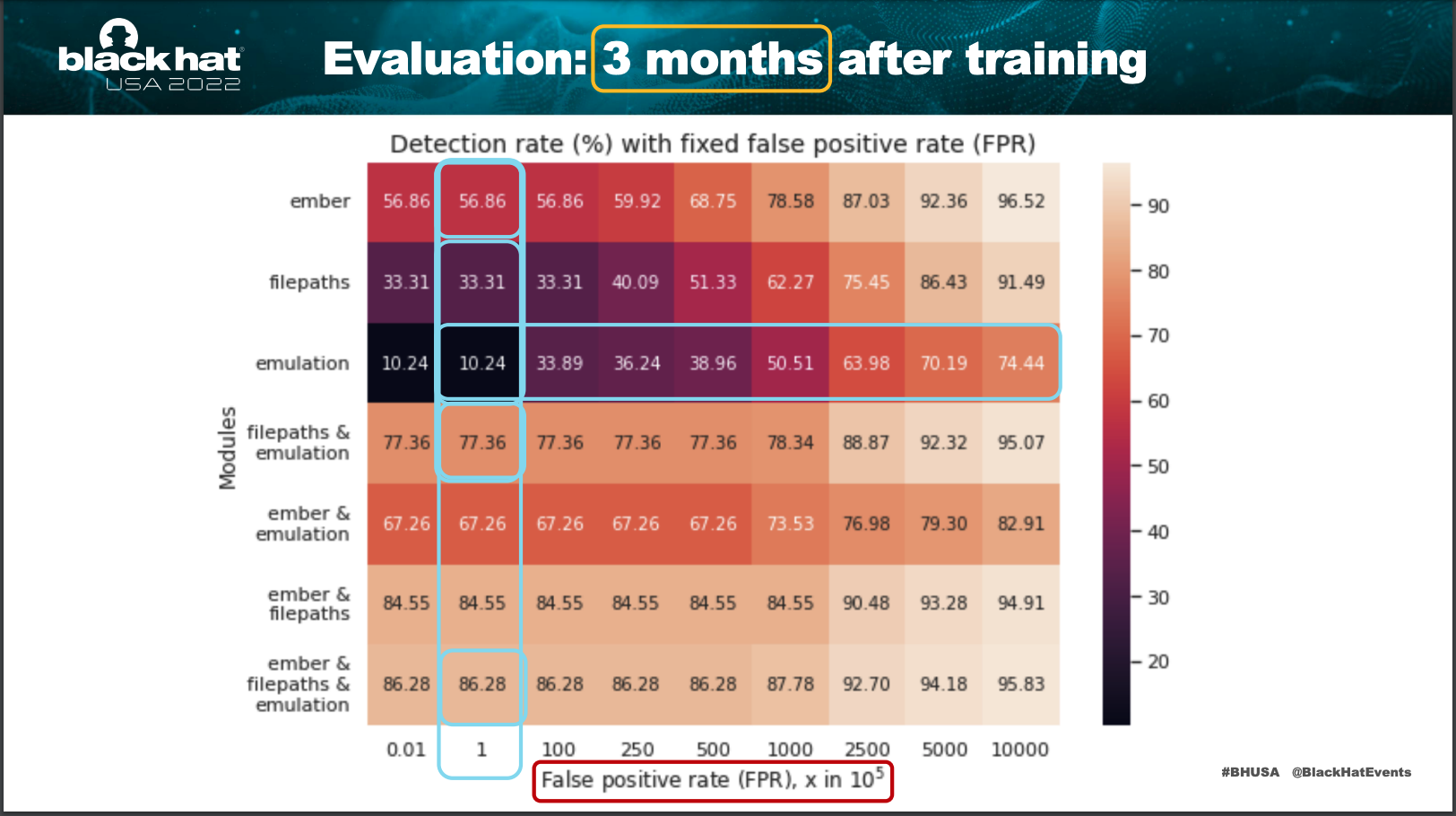
My Comments
- 我覺得結論中的 ‘ML is not a “silver bullet”, it is an extra tool" 這句話很傳神,目前很多 AI 應用其實都一直在挑戰傳統的解決方案,但事實上兩者應該嘗試融合並且合作,而非對立,ML 是一個很棒的 Classification 工具,但仍然無法取代或者解決一些更複雜細膩的問題。這次利用對 file path 的 NLP 建模結合 converlution 的 classification 就是期望解決路徑相似性的問題,希望藉由細微的特徵,來辨識是否是惡意路徑,而今天的議程就是在討論這個問題,並且提出了一個解決方案。效果仍然有限,但是這是一個很棒的開始,希望未來能夠有更多的研究可以進一步的發展。
OS: 真的要轉 NLP 的資料研究跟更熟習應用了,一堆議程都用到 NLP…
Human or Not: Can You Really Detect the Fake Voices?
[time= Aug 11, 2022 15:30 to 16:10]
- 此篇議程是 Lanzhou University 的學生在發表的,說的有點混亂,但概念上其實是在說明就 DeepFake 很像的概念,今天你正在面對的人跟聊天的對象,可能並不是你以為的那個人,因為人臉跟聲音都是假的。
- 本議程有提到現有的檢測方法其實效果都還不錯,且大多使用到 Computer Vision (CV, 計算機視覺) 的做法,也就是將聲音資訊轉換成圖像,再利用 Image Classification 的方式做分類,並且都有很高的準確率。e.g.,
- Neural Network Feature (NNF)-based approaches - ACM MM 2022 (Top Conference)
- End-to-End (E2E)-based approaches - Used in NLP problems
- Statistical-based approaches
- 這個議程主要是在說明他們發展了一套
SiF-DeepVC的 Speaker-irrelative Feature Deep Learning Voice Clone 的 Voice Clone,期望利用跟人聲無關的特徵來攻擊 FakeVoice Detecter 的方法,其假設在於利用這些所謂無關的背景、語速等等跟說話無關的特徵,來混淆 Detect Model,讓它無法正確判斷。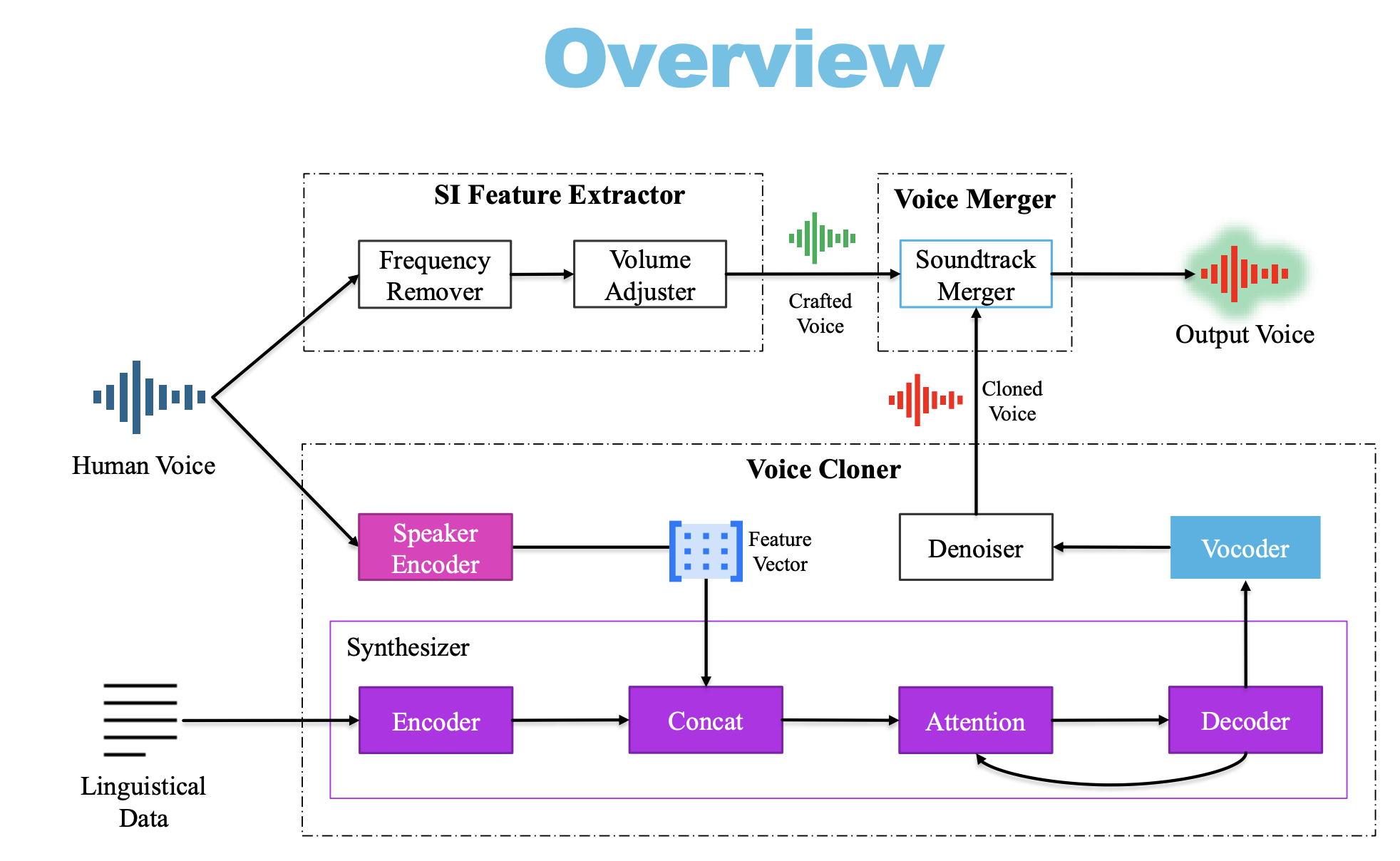
- 其中有提到一個很強的知識點在於,人聲主要頻率在 0.3kHz~3kHz,因此如果要去除人聲可以直接刪除 4kHz 以下的頻率,來保留噪音,相反要保留人聲可以先去除 0.3kHz 以下的頻率,再去除 4kHz 以上的頻率,來保留人聲。
- 當
Sif-DeepVC取得語音背景噪音之後,再將資料合成於一般的 VC 中,就可以欺騙 FakeVoice Detecter 了。 - 其實這也反應了一個很大的問題,就是目前市面上的 FakeVoice Detecter 其實並沒有考慮到這種情況,因為他們的假設是說,假如有人要偽造人聲,那他就會去偽造人聲,而不會去偽造背景噪音,因此這些 FakeVoice Detecter 都是以人聲為主,而忽略了背景噪音的問題。而在 Model Training 跟 Data Preprocessing 的過程中,也沒有先進行人聲保留的操作,而是把整段錄音丟進去,其實針對
Sif-DeepVC的破解方法非常簡單,就是放置 Noise Filter,但目前的 Detect Model 沒有人這樣做。 - 這次的 Speech 說明並且強調了,其實目前的 Fake Voice Detect 是失效的,先不提人耳根本就無法聽出合成的聲音或者真實的聲音的問題,現有的 Detect Model 其實還有實際應用的極大缺失。
My Comments
- 關於這種議題,我認為是屬於實體 Security Issue,因為這些技術在於偽造身份去做到社交工程 or 欺騙生物辨識系統,for example,偽造總統發言造成國際壓力和國內恐慌,或者偽裝 CEO 來店取得公司機密文件等等。
- 相較於 DeepFake 技術,我覺得 Voice Clone 的問題更加危險一些,因為人對於聲音的敏銳度其實並沒有眼睛對圖像的敏銳度高,而且往往我們會對聲音有一種認知上的信任,因此我認為這種技術的應用對於社會的影響會更加大。
- 這個 Speech 令我大開眼界的部分在於這是我少數看到針對 Noice 去做攻擊的部分,因為在我的認知之中,大部分的資料進入 model 做 detect 之前,應該都會經過一系列標準的資料歸一化過程,盡可能去除影響辨識的資料,當然也會有適當添加 Noise 來增加模型的泛化能力的做法,但相比直接利用調整 Noise 影響辨識,這種作法我是沒有想過的。
- 能夠理解為什麼 Detect Model 會失效,因為從頻譜中就可以看到這些語音的能量狀況已經可以說是完全被混淆摧毀了,而目前這些極度依賴 CV 的做法當然會在頻譜圖中失去焦點,而完全無法判斷是否是合成的人聲,這也放大了一個數據的問題就是頻域跟時域的轉換問題。
- 是否可以緩解,誠如上面所說如果今天 model 前準備一個 filter 針對語言特徵去做人聲的提取,再給 detect model 做辨識,應該就能解決這個問題了,但究竟有多少 system 目前有考慮到這個問題,我猜應該是不多的,因此這個部分的想法我真的覺得很新穎,也意外地揭露了其實很多偽造攻擊都仍然在嘗試突破各式檢測。
Locknote: Conclusions and Key Takeaways from Black Hat USA 2022
[time= Aug 11, 2022 16:30 to 17:10]
